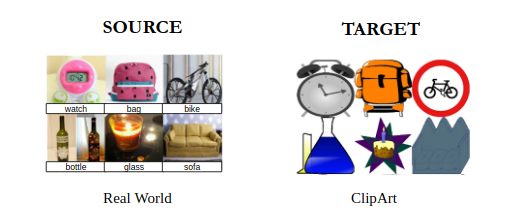
A major obstacle in adapting deep models to a target task is the shift in data distributions across different domains. This problem, typically referred as domain shift, has motivated research into Domain Adaptation (DA). Another major issue with deep networks is their inherent difficulty to learn sequentially over a large number of tasks without forgetting knowledge obtained from the previous tasks. This last problem is addressed by Continual Learning (CL) methods. We study DA and CL for several visual recognition and robot perception tasks.
Large Language and Vision Models for Visual Recognition
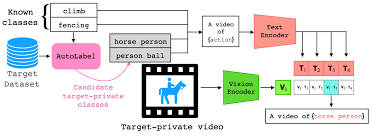
The field of computer vision has recently witnessed the emergence of a new generation of powerful deep architectures, trained on mammoth internet-scale image-text datasets. These models, commonly known as Large LanguageVision Models (LLVM) have become a cornerstone of modern computer vision research. These pre-trained LLVMs are now publicly available and can be easily integrated into any recognition system. We study how LLVMs can be applied to challenging tasks such as video action recognition and fine-grained classification.
Analysis of Social Scenes from Multimodal Data
Automated analysis of interactions in social scenes is critical for a number of applications such as surveillance, robotics and social signal processing. In this project we focus on the analysis of conversational groups and we address different tasks (e.g. human tracking, head and body pose estimation, F-formation detection) processing multimodal data gathered from camera networks and sensors mounted on humanoid robots.
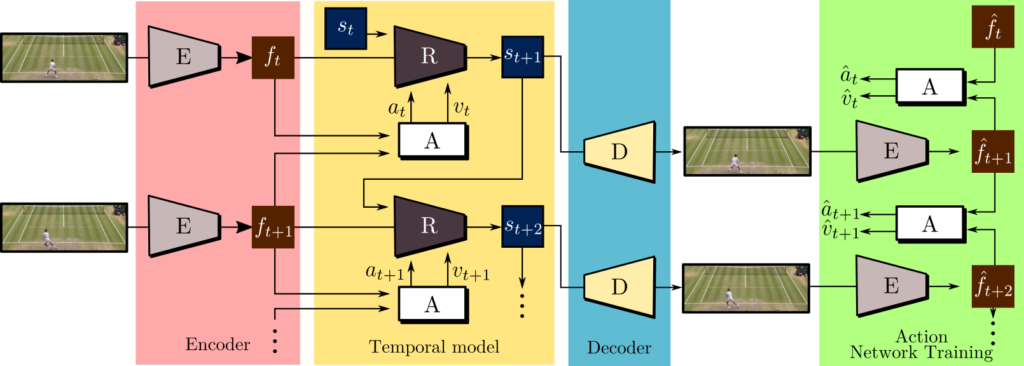
Playable Video Generation
We study the unsupervised learning problem of playable video generation (PVG), that is we aim at allowing a user to control the generated video by selecting a discrete action at every time step as when playing a video game. The difficulty of the task lies both in learning semantically consistent actions and in generating realistic videos conditioned on the user input.